- 技术(专利)类型 发明专利
- 申请号/专利号 201510952414.9
- 技术(专利)名称 一种优化阵列数据库并行数据加载性能的系统
- 项目单位
- 发明人 李晖 陈梅 李宏源 邱能俊
- 行业类别 人类生活必需品
- 技术成熟度 详情咨询
- 交易价格 ¥面议
- 联系人 李先生
- 发布时间 2021-03-10
 北京
北京
客服热线:010-83278899
 微信公众号 扫一扫 关注我们
微信公众号 扫一扫 关注我们
 北京
北京
客服热线:010-83278899
微信公众号 扫一扫 关注我们

项目简介
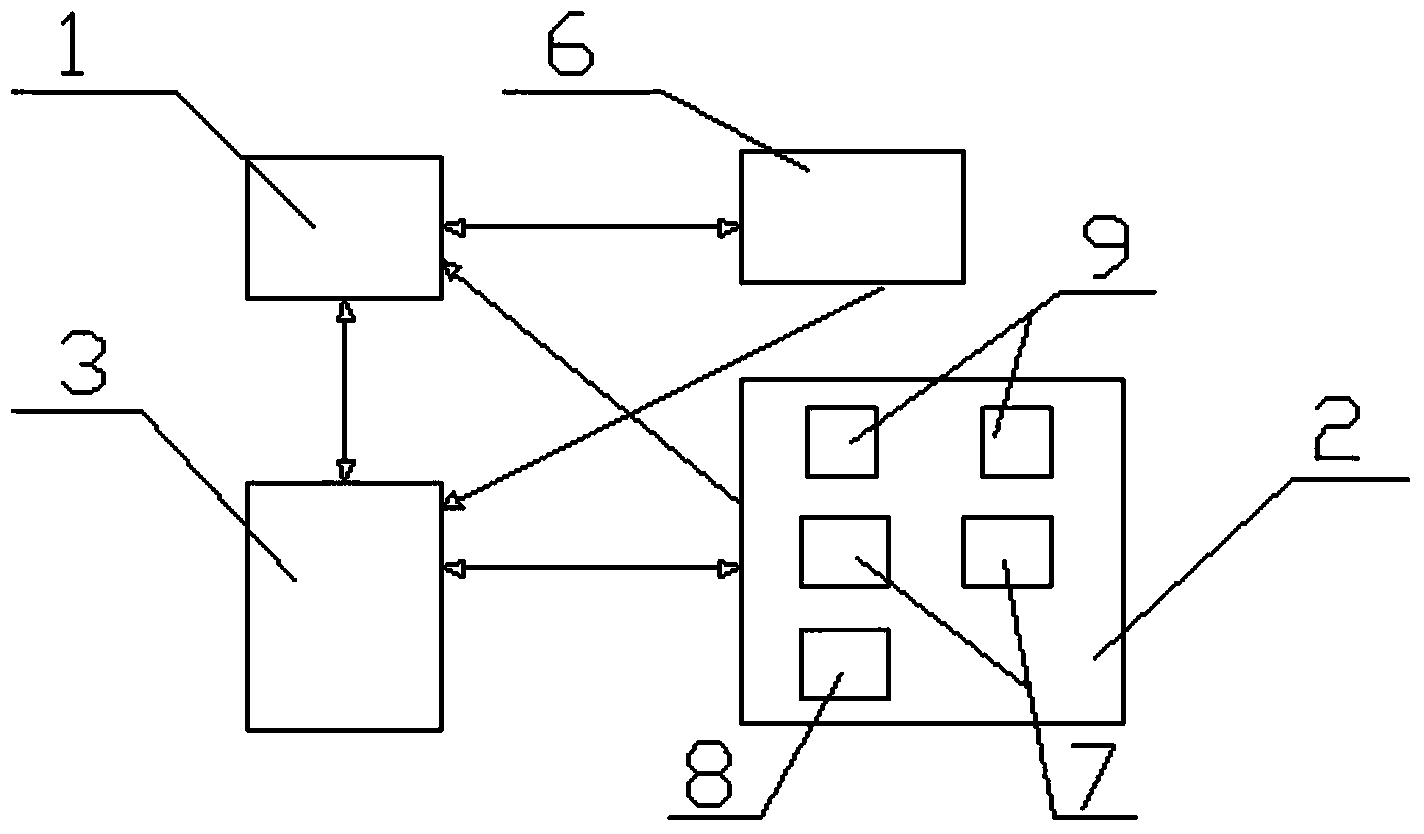
本发明公开了一种优化阵列数据库数据并行加载性能的系统,包括监控引擎(1),监控引擎(1)收集数据库集群(2)的监控信息,将监控信息反馈到FASTLoad系统组件(3),FASTLoad系统组件(3)根据监控信息对待加载的数据进行分配方法数据加载;监控引擎(1)用于实时监控数据库节点(7);数据库集群(2)用于数据加载的执行;FASTLoad系统组件(3)用于数据的分割处理和加载。本发明不仅能满足阵列数据的加载需求,而且是一种能够对大规模基于阵列模型的数据进行数据并行加载的科学数据管理工具系统,该系统性能是原有的数据库系统加载数据机制的性能的4到6倍。
说明书
技术领域
本发明涉及一种系统,特别是一种优化阵列数据库并行数据加载性能的系统。
背景技术
在大数据时代,在很多学科领域如生物信息学、气象学或者天文科学领域的科学数据增长非常迅速。而想要对这些数据进行分析和处理,需要先将数据导入到数据库中。随着数据量的增加,数据加载方法的性能变得越来越重要。SciDB是一个针对科学数据管理和分析的开源的科学数据库系统,它采用的是阵列数据(Array)模型,主要是由Stonebraker领导开发并且获得了Paradigm4公司的赞助。其设计初衷旨在解决科学研究中数据量大、数据世袭等科学问题。与传统DBMS不同的是,受益于阵列数据模型,SciDB能够为科学应用领域提供大规模的复杂分析支持,用以满足其日益增长的需求。SciDB主要的特征如下。首先是无覆盖特性,SciDB能够存储不同版本的数据,通过时间维度作为区别不同历史阵列的标志。此外,还采用压缩算法以节省空间。其次是引入了原位数据的特性,SciDB定义自己的数据格式,并为常用的外部数据格式提供适配器编写接口。通过适配器,用户就可以不通过加载数据到SciDB引擎直接进行数据分析处理。第三是命名版本特性:用户对阵列的一部分执行特定的变更,而保留其余部分不变。第四个特征是可以满足数据推导可重复性的要求的特征。尽管当前的阵列数据库如SciDB本身具有并行数据加载机制。但是由于这些数据加载机制本身采用的传统的关系型数据的加载策略,它们并不适合快速加载通常用阵列模型表示的科学数据到分布式并行系统中,尤其是在这些科学数据的数据大小以及维度变得很大的情况下,传统数据加载方法的性能下降将较为明显。为了优化阵列数据库数据并行加载的性能,我们针对阵列数据库的数据加载过程提出了一种优化的并行加载系统FASTLoad。
发明内容
本发明的目的在于,提供一种优化阵列数据库的数据并行加载性能的系统。本发明不仅能满足阵列数据的加载需求,而且是一种能够对大规模基于阵列模型的数据进行数据并行加载的科学数据管理工具系统,该系统性能是原有的数据库系统加载数据机制的性能的4到6倍。本发明的技术方案:一种优化阵列数据库数据并行加载性能的系统,包括监控引擎,监控引擎收集数据库集群的监控信息,将监控信息反馈到FASTLoad系统组件,FASTLoad系统组件根据监控信息对待加载的数据进行分配方法数据加载;监控引擎用于实时监控数据库节点;数据库集群用于数据加载的执行;FASTLoad系统组件用于数据的分割处理和加载。前述的优化阵列数据库数据并行加载性能的系统中,所述FASTLoad系统组件包括数据分区引擎,数据分区引擎分析待加载的数据,将待加载的数据文件分割成子文件,然后将子文件加载到数据加载协调引擎,数据加载协调引擎根据监控信息对待加载的数据子文件按照分配方法协调数据库节点参与数据加载任务,数据加载完成后,阵列数据库集群的协调者节点将更新自己的元数据。前述的优化阵列数据库数据并行加载性能的系统中,所述的监控引擎将监控信息存储在系统状态数据库中,系统状态数据库再将监控数据传送到FASTLoad系统组件中。前述的优化阵列数据库数据并行加载性能的系统中,所述的数据库集群包括协调者和数据库节点,数据库节点连接有监控客户端,监控客户端负责收集数据库节点的性能和系统状态信息,并反馈到系统状态数据库中。前述的优化阵列数据库数据并行加载性能的系统中,所述的数据库集群设置1个以上数据库节点。前述的优化阵列数据库数据并行加载性能的系统中,所述监控引擎的采集数据包括:CPU利用率、内存量、磁盘读写速率、网络带宽利用率、过去t(600≤t≤7200)秒内任务的平均等待时间、任务数量等数据库节点负载。前述的优化阵列数据库数据并行加载性能的系统中,基于下述分配方法来安排数据库节点参与数据加载任务:(1)如果数据加载任务T及其子任务TA在某数据库节点上运行时所需要的内存量,小于该数据库节点的可用内存量的m%,则将该数据加载任务T及其子任务TA加入到任务队列中,等待执行;如果该数据加载任务T被指明为紧急任务,则将该数据加载任务T及其子任务TA在该数据库节点的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务的执行;其中,0<m%≤80%;(2)如果某数据库节点上的磁盘读写速率不到最高速度的d%,则将数据加载任务T及其子任务TA加入到任务队列中,等待执行;如果该数据加载任务T被指明为紧急任务,则将该数据加载任务T及其子任务TA在该数据库节点的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务的执行;其中,0<d%≤60%;(3)如果某数据库节点上当前正在等待执行的任务队列中的任务,其预估的平均等待时间小于t1秒,则将该数据加载任务T及其子任务TA加入到任务队列中,等待执行;如果该数据加载任务T被指明为紧急任务,则将该数据加载任务T及其子任务TA在该数据库节点的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务的执行;其中,600≤t1≤7200;(4)如果所有的数据库节点的负载都重,按照前述3条规则没有挑选到合适的执行数据加载任务的数据库节点,那么将数据加载任务T分成X个子任务,然后按照在过去的时间t2内,任务队列中的平均等待时间短的数据库节点优先的原则,将数据加载任务T及其子任务TA予以分配执行;对于任务平均等待时间相同的数据库节点,则按照可用内存量大、CPU利用率低的优先原则,进行任务分配;如果该数据加载任务T被指明为紧急任务,则将数据加载任务T及其子任务TA在该数据库节点的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务T的执行;其中,600≤t2≤7200,N/2≤X≤N。与现有技术相比,本发明通过监控引擎收集数据库集群的监控信息,将监控信息反馈到FASTLoad系统组件,FASTLoad系统组件中的数据加载协调引擎根据监控信息,应用自定义的规则来安排一部分数据库集群节点参与数据并行加载任务的执行。根据参与执行任务的各数据库节点的可用内存情况,FASTLoad系统组件中的数据分区引擎分析待加载的数据,将待加载的数据文件进行分割,然后协调参与执行任务的各数据库节点并行的执行数据加载任务,系统性能可达到原有数据库系统加载数据机制的性能的4到6倍。申请人将本申请的FASTLoad系统和SciDB内置的数据并行加载系统进行了一系列对比实验,实验设计与性能分析如下:实验配置使用了15个KVM虚拟机节点。每个虚拟机节点都有一个虚拟出的4核4线程CPU,50GBswap大小以及1TB硬盘空间。作为SciDB集群的Coordinate节点(协调者节点)拥有40GB主存,而作为worker节点(数据库节点,又称工作者节点)的其他所有KVM虚拟机节点都只拥有8GB主存。所有的虚拟机节点是由两台物理机虚拟化出来的。每台物理机都拥有两个主频为2.0GHz的Intel(R)Xeon(R)E5-2620cpu(每个CPU有6个核心12个线程)。这两台物理机总共拥有192GB主存和14TB的硬盘存储。任意两个虚拟节点之间的稳定传输速度大概是20M/s左右。数据来源为了做FASTLoad系统与SciDB内置的数据并行加载系统之间的性能对比,我们采用了9中不同规格的数据集做性能评估。这些数据集来自美国斯隆数字化巡天(SDSS)。每个数据集的大小以及该数据集中包含的数据的条数参见表1。表1性能分析结果从图3中,我们可以看出从第1种规格数据集到第四种规格数据集,FASTLoad系统与SciDB内置的数据并行加载系统的性能看起来相差不大。因而,我们将图3中数据集大向小于54GB部分作为图4。从图4中可以看出,当数据集大小小于33GB时,尽管数据加载时间总体上呈现出增长的趋势,但是这两种加载方式的性能差别不大。当数据集大小超过43GB,FASTLoad系统与SciDB内置的数据并行加载系统之间的性能差距越来越大。为了可以更加明显的看出两者之间的差距,我们把这一部分放在图5中。从图5中,我们可以看到在数据集大于43GB时,FASTLoad明显比SciDB内置的数据并行加载系统更高效。从图5中可以看出,FASTLoad机制性能是SciDB内置的数据并行加载机制性能的4到6倍。甚至当数据集只有43GB时,FASTLoad机制的数据并行加载都比SciDB内置的数据并行加载机制性能快数百秒。
附图说明
图1是本发明的基础构架框图;图2是本发明的FASTLoad组件工作原理框图;图3是FASTLoad系统与SciDB内置的数据并行加载系统的性能表现对比图;其中,横坐标为数据量,纵坐标为数据加载时间;正方形连接为FASTLoad的性能,圆形连接的为SciDB内置数据并行加载系统的性能;图4是图3中数据集大向小于54GB部分;其中,横坐标为数据量,纵坐标为数据加载时间;正方形连接为FASTLoad的性能,圆形连接的为SciDB内置数据并行加载系统的性能;图5是数据集大小超过43GB,FASTLoad系统与SciDB内置的数据并行加载系统之间的性能表现对比图。其中,横坐标为数据量,纵坐标为数据加载时间;正方形连接为FASTLoad的性能,圆形连接的为SciDB内置数据并行加载系统的性能;附图中的标记为:1-监控引擎,2-数据库集群,3-FASTLoad系统组件,4-数据加载协调引擎,5-数据分区引擎,6-系统状态数据库,7-数据库节点,8-协调者,9-监控客户端。
具体实施方式
实施例1。一种优化阵列数据库数据并行加载性能的系统,包括监控引擎1,监控引擎1收集数据库集群2的监控信息,将监控信息反馈到FASTLoad系统组件3,FASTLoad系统组件3根据监控信息对待加载的数据进行分配方法数据加载;监控引擎1用于实时监控数据库节点7;数据库集群2用于数据加载的执行;FASTLoad系统组件3用于数据的分割处理和加载。所述FASTLoad系统组件3包括数据分区引擎5,数据分区引擎5分析待加载的数据,将待加载的数据文件分割成子文件,然后将子文件加载到数据加载协调引擎4,数据加载协调引擎4根据监控信息对待加载的数据子文件按照分配方法协调数据库集群2中的数据库节点7参与数据加载任务,数据加载完成后,阵列数据库集群的协调者8节点将更新自己的元数据。以便反应出最新的数据分布情况和统计信息。所述的监控引擎1将监控信息存储在系统状态数据库6中,系统状态数据库6再将监控数据传送到FASTLoad系统组件3中。所述的数据库集群2包括协调者8和数据库节点7,数据库节点7连接有监控客户端9,监控客户端9负责收集数据库节点7的性能和系统状态信息,并反馈到系统状态数据库6中。所述的数据库集群2设置1个以上数据库节点7。所述监控引擎1的采集数据包括:CPU利用率、内存量、磁盘读写速率、网络带宽利用率、过去t(600≤t≤7200)秒内任务的平均等待时间、任务数量等数据库节点负载。基于下述分配方法来安排数据库节点7参与数据加载任务:(1)如果数据加载任务T及其子任务TA在某数据库节点7上运行时所需要的内存量,小于该数据库节点7的可用内存量的m%,则将该数据加载任务T及其子任务TA加入到任务队列中,等待执行;如果该数据加载任务T被指明为紧急任务,则将该数据加载任务T及其子任务TA在该数据库节点7的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务的执行;其中,0<m%≤80%,本系统默认设置m%=80%,本数据库系统的系统管理员可以根据系统实际运行情况对本参数进行调整;(2)如果某数据库节点7上的磁盘读写速率不到最高速度的d%,则将数据加载任务T及其子任务TA加入到任务队列中,等待执行;如果该数据加载任务T被指明为紧急任务,则将该数据加载任务T及其子任务TA在该数据库节点7的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务的执行;其中,0<d%≤60%,本系统默认设置m%=60%,本数据库系统的系统管理员可以根据系统实际运行情况对本参数进行调整;(3)如果某数据库节点7上当前正在等待执行的任务队列中的任务,其预估的平均等待时间小于t1秒,则将该数据加载任务T及其子任务TA加入到任务队列中,等待执行;如果该数据加载任务T被指明为紧急任务,则将该数据加载任务T及其子任务TA在该数据库节点7的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务的执行;其中,600≤t1≤7200,本系统默认设置t1=600,本数据库系统的系统管理员可以根据系统实际运行情况对参数进行调整。预估的平均等待时间的取值为本数据库节点在过去t秒内的任务平均等待时间;(4)如果所有的数据库节点7的负载都重,按照前述3条规则没有挑选到合适的执行数据加载任务的数据库节点7,那么将数据加载任务T分成X个子任务,然后按照在过去的时间t2内,任务队列中的平均等待时间短的数据库节点7优先的原则,将数据加载任务T及其子任务TA予以分配执行;对于任务平均等待时间相同的数据库节点,则按照可用内存量大、CPU利用率低的优先原则,进行任务分配;如果该数据加载任务T被指明为紧急任务,则将数据加载任务T及其子任务TA在该数据库节点7的任务等待队列中进行插队,将其排到队列的最前面,等待当前正在执行的任务执行完后即可进行数据加载任务T的执行;其中,600≤t2≤7200,N/2≤X≤N,N是数据库节点的数量,X的取值的确定方法为:在[N/2,N]的区间内随机的取一个整数,该整数值就是X的取值。本系统默认设置t2=600,本数据库系统的系统管理员可以根据系统实际运行情况对参数进行调整。数据加载流程可以分为两种类型。如果用户需要马上加载当前的数据,那么用户的数据文件信息会马上转发给FASTLoad系统组件3,同时,该信息会带有一个标识说明该文件必须马上导入到集群中。之后FASTLoad系统组件3会等待直到数据加载协调引擎4处于空闲状态。一旦数据加载协调引擎4处于空闲状态,数据加载任务会立即执行。如果用户不需要马上把数据加载到数据库集群2中,那么该数据加载任务会被加载到一个任务队列中排队,同时该任务数据信息会被发送到监控引擎。这意味着数据流会被按照系统默认的大小作为文件放置,并且会被记录下当前收到的数据的行数,假设系统默认的最大行数为n。一旦数据流传输超过n行的数据,那么已经接收的n行数据会在一个文件中单独存储。同时,此时的文件状态会被存储在数据库中。文件状态和文件数据相互之间是联系在一起的。之后文件的所有数据按文件加载次序发到FASTLoad系统组件3中,FASTLoad系统组件3会调用数据加载协调引擎4按照任务次序把数据加载到数据库集群2中。上述两种方式都会将要加载数据文件的状态信息发给系统状态数据库6。数据分区引擎5用于决定如何分割数据文件。在数据加载过程中,我们的加载方法可以避免出现主存瓶颈。一旦数据加载失败,数据加载过程会重新进行直至成功或者系统默认的最大重试次数。数据分区引擎5是一个简单的实现了先来先服务算法的调度器。这意味着数据加载次序是数据加载请求发送给数据分区引擎5的次序。一旦数据加载失败,该数据的加载次序依旧不变。假设当前数据文件的加载次序为X,那么假如当前文件加载失败,那么次序为(X+1)的数据文件加载过程不会被调度。如果该数据文件加载重试次数超过了系统默认的最大重试次数,那么该任务的相关信息以及失败信息会发送到状态存储子系统中去,从而方便管理者做进一步的排查。FASTLoad组件主要由数据分区引擎5和数据加载协调引擎4组成。对于每个将参与执行数据加载任务的数据库节点7,数据分区引擎5(分割器引擎)负责将需要加载的文件分割成块,每个块的大小小于将要把它加载到数据库集群2中的对于数据库节点7可用内存量。数据分区引擎5会在分割任务结束后将相关信息发送给数据加载协调引擎4,然后由它通知相应的数据库节点7开始执行相应的数据加载子任务。

企业营业执照
专利注册证原件
身份证
个体户营业执照
身份证
专利注册证原件
专利代理委托书
转让申请书
转让协议
手续合格通知书
专利证书
专利利登记簿副本





提交

公众号
全国技术转移公共服务平台